2024年10月1日,由北京大学定量生物学中心/北大-清华生命科学联合中心李志远课题组牵头,联合南京农业大学LorMe实验室和苏黎世大学定量生物医学系Rolf Kümmerli教授在国际学术期刊eLife上发表了题为“From sequence to molecules: Feature sequence-based genome mining uncovers the hidden diversity of bacterial siderophore pathways”的研究论文。论文开发出了一种创新的生物信息学流程,成功揭示了假单胞菌铁载体pyoverdine途径的隐藏多样性,为细菌次级代谢的研究提供了全新的研究范式。

图1 从序列到分子:揭示铁载体通路的多样性
导读
微生物次级代谢产物在菌群互作研究和药物发现中具有重要作用。近年来,随着高通量测序技术的飞速发展,科学家对微生物群落的理解得到了极大提升,尤其是在微生物多样性和生态功能方面的研究。然而,尽管已有许多生物信息学工具可以用于识别微生物基因组中的次级代谢产物合成基因簇,但要精确预测这些产物的具体结构和功能仍然面临诸多挑战。这主要是由于次级代谢途径通常由复杂的模块化酶系统主导,而这些酶的底物特异性及功能难以通过现有数据准确预测。
本研究开发了一种新的生物信息学管道,专注于预测铁载体pyoverdine这一模式次级代谢物,该管道基于改进的基因注释,并结合基于系统发育和特征序列的底物预测技术,能够从基因组片段中准确识别 pyoverdine 合成基因簇,准确预测其结构组成和识别其对应的受体基因。这一创新方法大幅提升了次级代谢产物预测的准确性,揭示了一个之前未被充分认知的代谢多样性,具备广泛的应用前景:不仅为微生物次级代谢的深入研究提供了有力工具,还为新药开发、微生物代谢工程等领域开辟了新的方向。

图2 本文开发的基因组挖掘管道,以精确预测假单胞菌属菌株产生的铁载体pyoverdine的生物合成、分子结构和受体摄取
机制
主要结果
首先,本研究开发了一种改进的四步注释流程,用于准确注释假单胞菌的铁载体pyoverdine合成酶的基因簇,系统分析了9599个假单胞菌基因组的铁载体pyoverdine合成基因簇,最终去除重复基因组获得1664个pyoverdine生产者和264个非生产者,它们遍布所有主要的假单胞菌物种分支(图3)
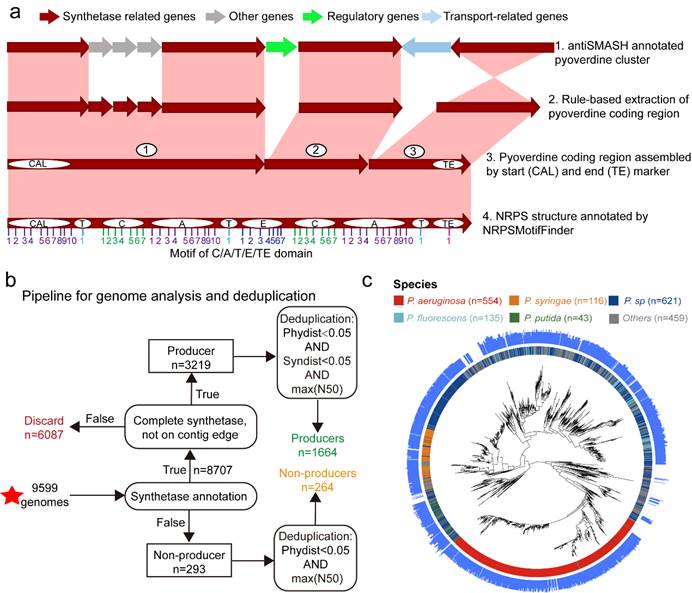
图3 改进的注释管道揭示了pyoverdine合成基因的多样性
本研究的下一个目标是精确预测 1664个具有完整合成酶基因簇的菌株所产生的pyoverdine分子结构。首先,通过分析13种已知pyoverdine结构和非核糖体肽合成酶(NRPS),从中识别出101个有确定氨基酸底物对应的A结构域序列。通过特征序列提取和序列距离计算以及聚类方法选择优化了A结构域底物预测的精确性。然后,将1664个pyoverdine生产者包含的18292个A结构域与101个参考A结构域进行比较,基于特征序列距离开发了一种“以系统发育为中心”的预测算法确定每个查询A结构域的底物。最后,通过双盲的方式分别在两个实验室开展pyoverdine结构预测和结构解析实验。我们在北京大学对20株假单胞菌进行pyoverdine结构预测,同时合作者Rolf在苏黎世大学采用 UHPLC-HR-MS/MS 技术解析了这20株菌所产pyoverdine的真实结构。结果显示预测与观察的结构匹配率高达 94.4%(160个氨基酸中有151个准确分配)。相比传统方法 antiSMASH(58.8% 准确率),本研究开发的方法显著提高了结构预测的准确率。未匹配的9个氨基酸中,包括无法区分的赖氨酸和鸟氨酸,以及对于缬氨酸、瓜氨酸和组氨酸等未在参考集中出现的底物预测为“未知”,只有两种情况(0.8%)表示观察到的氨基酸和预测的氨基酸之间存在真正的不匹配。总而言之,本研究开发的以系统发育为中心的预测管道在预测pyoverdine肽结构和识别假单胞菌中的未知底物方面非常准确(图4)。

图4 pyoverdine合成酶组装线的以系统发育为重点的底物预测
本研究将上述pyoverdine合成基因注释和结构预测的生物信息学流程推导出了这1664个菌株产生的pyoverdine结构,预测产生了188种不同的pyoverdine结构(图5),其中仅37种结构曾有报道。这37种结构在大部分菌株中高度丰富(1103个菌株),而本研究在识别更多更罕见的pyoverdine变体方面非常强大。值得注意的是,pyoverdine结构的多样性与系统发育没有强相关性,表明不同物种间存在pyoverdine合成基因的频繁重组与水平基因转移。总体而言,本研究开发的生物信息学方法能够高精度地预测 pyoverdine结构,揭示了假单胞菌中铁载体的多样性和进化史,并发现了151种新的pyoverdine变体。

图5 pyoverdine结构多样性映射到1928个假单胞菌菌株的系统发育树上
本研究继续开发了一种基于关键序列的 FpvA 受体注释方法,用于在假单胞菌基因组中注释FpvA受体。FpvA是TonB依赖性受体,负责将铁-pyoverdine复合物转运到周质中。本研究利用多序列比对和pHMM计算得出FpvA和 FpvB受体的关键识别区域,命名为R1和R2。R1区域用于区分其他受体与FpvA、FpvB 受体,R2区域则区分FpvA和 FpvB受体。基于这些关键识别区域的评分,本研究开发了一个决策流程图来注释假单胞菌基因组中的FpvA受体(图6)。

图6 用于注释FpvA受体的基于序列区域的鉴定管道
将基于关键序列的受体注释管道应用于1928个假单胞菌基因组,成功识别出4547个FpvA、615个FpvB和9139个其他TonB依赖性Fpv受体(图7)。将4547个FpvA序列与一直FpvA序列进行序列相似性分析,其中2254个FpvA序列与已知参考序列相似性低于50%。进一步分析发现,92%的FpvA基因在基因组上位于其对应的pyoverdine 合成基因的20 kb范围内,验证了 FpvA 受体注释方法的可靠性。通过分析1534个位于pyoverdine 合成基因20 kb范围内的FpvA受体的序列特征,发现四个位于Plug结构域附近的区域对FpvA的分组识别能力最强。这些高分区域与pyoverdine选择性相关,并用于开发“特征序列”以增强序列聚类的准确性。应用特征序列识别出94组FpvA,其中43个组包含超过10个成员,显示出远超预期的受体多样性(94组中只有3组被报道)。

图7 将受体注释管道应用于1928个假单胞菌基因组
总结
本研究开发了一系列生物信息学注释流程,用于重建由假单胞菌产生的铁载体——pyoverdine的完整代谢途径。通过结合知识引导学习和基于特征序列的方法,该管道成功注释了pyoverdine的合成酶和受体,并准确预测了pyoverdine的结构组成。研究表明,基于完整基因序列的比对无法准确预测功能信息,提取与功能密切相关的特征序列更加有效。通过该方法,研究发现了许多新的 FpvA受体和pyoverdine。此外,本研究注释流程在基因组草稿数据中表现良好,并显示出扩展到其他微生物次级代谢产物的潜力。通过逐步改进算法和结合实验验证,可进一步提高预测精度且自动化分析流程可应用于大规模次级代谢产物的研究。
该工作的第一作者为北京大学定量生物学中心/北大-清华生命科学联合中心的博士后顾少华和研究生邵远哲,通讯作者为南京农业大学的韦中教授,苏黎世大学定量生物医学系Rolf Kümmerli教授, 和定量生物学中心/北大-清华生命科学联合中心研究员李志远。相关工作得到了北大-清华生命科学联合中心,以及国家重点研发计划(2021YFF1200500)和国家自然科学基金委员会项目(42107140,41922053,32071255,T2321001)和博新计划(BX2021012)的资助。







